
Predicting startup success with low code machine learning and GPT-4.
How quickly, with little data and with very little coding skills build ML sourcing models.

Andre Retterath recently published a report on the Data-driven VC Landscape. If you don’t know Andre and are interested in data-driven VC investing, you must check his substack, which is the coolest source of information on the topic out there! In the report, he defines that data-driven VCs should have at least one engineer in their team and should be proven to develop internal tooling in at least one segment of the value chain. That is probably what it takes to become a truly data-driven investor. The report mentions 151 such firms, including some very big names.
To hire an engineer, you’d need, let’s say, €100k/year. Another €40-50k will be needed for tools and data. It will take considerable time for the engineer to understand Venture Capital. If she doesn’t leave in the meantime for a more exciting opportunity, you should be ready to start building something after one year. Given that the median size of a fund in Europe is around €70mil, I can imagine many GPs won’t be inclined to invest hundreds of thousands in building internal tooling until they have confidence that this will create value for the firm.
I tried to figure out how to build an ML sourcing tool and become more data-driven with no engineer and essentially no budget. I developed an ML tool to predict the success of startup companies, aiming to code as little as necessary. I used a small amount of data from Pitchbook and enriched the data set using Open AI’s GPT-4. I trained ML models using Azure AutoML. I had to write scripts asking queries to GPT-4 and scripts to process data, although a lot of processing, like filling in missing values in a data set, can be done with Azure AutoML. The whole project took me a few days and a few hundred $ in the cost of Azure and Open AI’s APIs. The performance of my ML tool is better than good. While there are certainly many nuances to consider, the best models I (or rather Auzre AutoML) developed arguably outperform human investors.
Success definition
I was predicting the success of startup companies defined as exit through IPO, M&A > $100m or unicorn status within 8 years from series A round. Because I had only 4,000 companies in the data set (damn Pitchbook download limits), I was a bit restricted when deciding about the success definition as I needed a sample of probably at least 400 positive class instances. I used only information known at the time of series A as if models were series A investors.
If you want to predict the success of startup companies using ML, one of the biggest challenges is to build a good data set. It is costly to buy data, it is fairly difficult to scrape data from the internet, and it is technically challenging to match data from different sources. Here, with help came GPT-4. I only had data on companies and deals from Pitchook, and I enriched the data set using GPT -4.
Enriching data with GPT-4
I used GPT-4 to retrieve ‘hard’ information and (inspired by the paper of Dominik Dellerman, who employed human experts in his Hybrid Intelligence Model) to get ‘soft’ human expert-like assessments. I retrieved from GPT information on founders’ education (degrees, majors, universities), if they were serial entrepreneurs, on business model characteristics and products. I also asked GPT-4 to assess the quality of founders’ education, scalability of a business model, product innovativeness and quality of seed investors. Features generated with GPT-4 had an aggregated importance of 0.49 (incl. 0.29 for ‘soft’ information), while features generated based on Pitchbook information had an aggregated importance of 0.51. This means that GPT-generated features were almost equally useful for predicting the success of startup companies as data from Pitchbook.
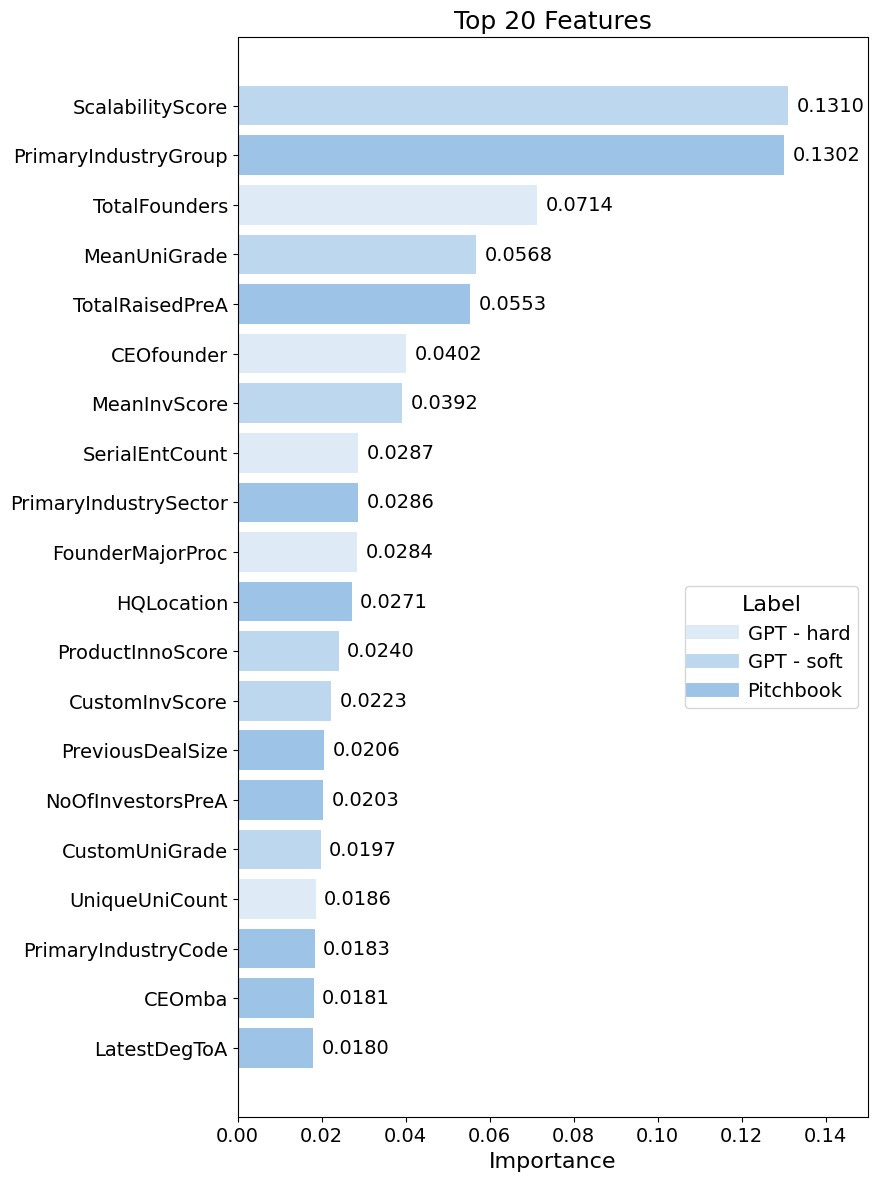
‘Soft’ information generated with LLMs makes it possible to achieve good real-world results despite the small size of a training data set. For example, I used GPT-4 to assign to universities graduated by founders scores based on their places in rankings. In such cases, it is not required to have specific information (name of university) in a training data set for this information to be useful for making predictions. GPT will assign a score to a university whose name has been never seen by an ML model, and the model will know what to do with such a score. Stay tuned; I’ll dedicate a separate article to generating ‘soft’ information-based features using LLMs.
Results
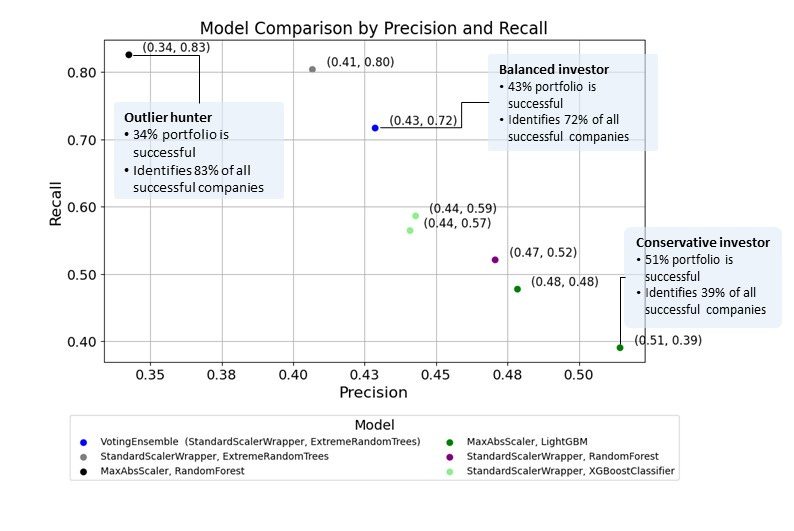
I trained several models, and if they were investors, they would build portfolios consisting of between 34 and 51% of successful companies (precision), identifying between 39 and 83% of all successful companies (recall) in a data set. There is a trade-off between the two, and the decision of how to tune a model or which model to choose should be based on a use case and your risk appetite. However, given that VC investing is an outlier hunting, I’d opt for StandardScalerWrapper, ExtreemeRandomTrees, which would identify 80% of all successful companies and build a portfolio with 41% of successful companies.
With some extra work or creativity, I’m sure it’s possible to generate much more information with a predictive value using GPT and achieve even better results.
If you want to know anything more about the project, hit me up and subscribe for more articles on how non-engineers can build tools to help them become a more data-driven investor.
That’s so cool. Do you have a more detailed version of the project? And how much coding knowledge had you before doing the project?